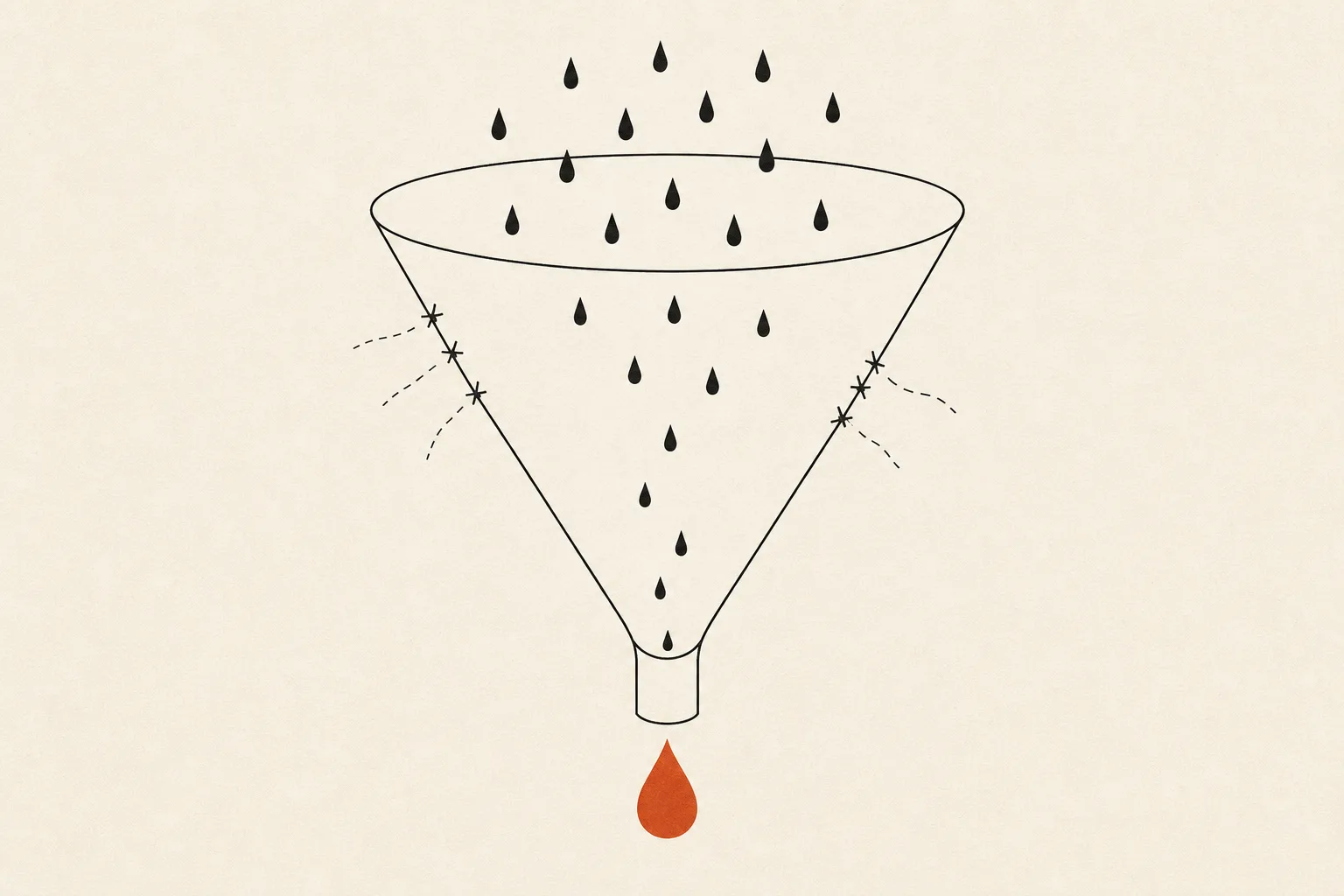
Centralised
data
Your data lives in the CRM, the ERP, billing, three spreadsheets and an inbox. None of them talk to each other. We bring them into a lightweight warehouse, without the budget or weight of heavy machinery.
Your data already exists. It's simply scattered across ten tools that don't talk to each other, duplicated, and named differently in each.
§ Our stance
An SME doesn't need a factory. It needs something that works fast.
The six-figure, eighteen-month data warehouse isn't built for you. It's designed for large groups, dedicated data teams, budgets that absorb a slipping project. The SME, meanwhile, pays for the slip with blind steering.
We deploy a lightweight warehouse, sized for your real volumes, plugged into your existing tools in weeks. It scales without a rewrite the day you grow. No factory: a clean base, fast.
Four moves to bring data together.
Source inventory
Flow connection
Dedup + definitions
One reliable base
Operational in weeks, not years.
Four to six weeks for a connected, reconciled warehouse, against the eighteen months of a classic project. We deliver in useful steps, not a big bang.
- 01 Source mapping
We inventory data, definitions and owners. The map is validated before any technical brick.
- 02 First flows connected
Priority sources are synchronised by incremental flow. The warehouse starts filling on its own.
- 03 Reconciliation and quality
Duplicates merged, identifiers aligned, definitions unified. Quality rules run continuously.
- 04 Base opened to uses
Steering, reporting and AI agents draw from one base. The team is trained, extension happens source by source.
One base, four markers.
An industrial SME.
A dozen sources unified without an eighteen-month project.
We thought we needed a big data project. What we mostly needed was for the figures to finally meet in one place.
Operations leadership, industrial SME
What ingests, sorts
and serves.
| Category | Tool | Role |
|---|---|---|
| Data warehouse | DuckDB · BigQuery · Snowflake | Warehouse sized for SMEs, scaling without rewrite. |
| Volume model | Claude Haiku 4.5 | Deduplication, identifier reconciliation and bulk normalisation. |
| Reasoning model | Claude Sonnet 4.6 | Schema mapping, indicator definitions and quality rules. |
| Connectors | HubSpot · Salesforce · SAP · Sage · Stripe | Connectors to the business tools that already hold the data. |
| Ingestion | Airbyte · Fivetran | Inbound flow synchronisation, incremental and scheduled. |
| Durable workflow | LangGraph | Pipeline orchestration, quality control, failure recovery. |
Before we unify.
Q.01 How is this different from a real enterprise data warehouse?
The same logic, sized for your volumes. We use engines that scale (DuckDB, BigQuery, Snowflake) but deploy the useful scope in weeks, not a group project in eighteen months. You pay for what you need now.
Q.02 Do we need to replace our existing software?
No. The warehouse plugs via connectors into what you already have: CRM, ERP, billing, spreadsheets. Nothing is replaced, everything is aggregated and reconciled on read.
Q.03 How do you handle duplicates and divergent definitions?
A client becomes one client: duplicates are merged, identifiers aligned, and each indicator gets a definition validated with you. The base then stays clean, continuously checked by quality rules.
Q.04 What happens to the data the day we grow?
The warehouse scales without a rewrite. We size for today and the architecture absorbs growth: more volume, more sources, without redoing the project.
Data unified.
One truth.
45 minutes. We map where your data lives today, we price the most useful warehouse. If we have nothing to offer, we say so.